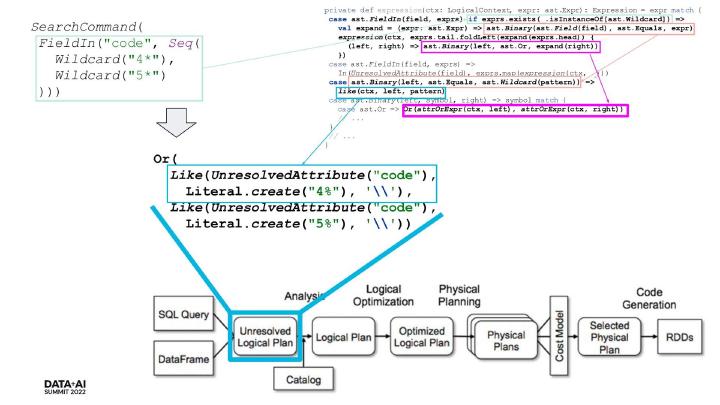
Reverse-Engineering a Search Language
This goes about a couple architectural and organizational approaches on achieving Distributed Data Mesh, which is essentially a combination of mindset, fully automated infrastructure, continuous integration for data pipelines, dedicated departamental or team collaborative environments, and security enforcement.
Learn how seemingly impossible things are real with the right approach.
See Also
- Accelerating SIEM Migrations With the SPL to PySpark Transpiler (external)
- Data Lineage in Context of Interactive Analysis (talk)
- Building Databricks Integrations With Go (talk)
- Building Robust Python Applications on Top of Databricks (talk)
- Upgrading Between Databricks Runtime Versions Made Easier (external)