OSS Year 2022 in Review: Projects Launched
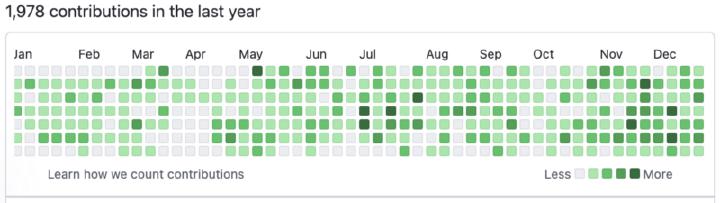
Okay, it’s this time of the year, and everyone is checking their GitHub stats. I’ll join the pack on my OSS summary for the year 2022. Here’s a short recap with my own thoughts about the four projects I’ve been driving.
Read more about OSS Year 2022 in Review: Projects Launched