Strategies for Data Quality With Apache Spark

In fact, many data teams are guilty of overlooking critical questions like “Are we actually monitoring the data?” after deploying multiple pipelines to production. They might celebrate the success of the first pipeline and feel confident about deploying more. Still, they need to consider the health and robustness of their ETL pipeline for long-term production use. This lack of foresight can lead to significant problems down the line and undermine trust in the data sets produced by the pipeline. In the previous post we’ve scratched the surface of how one can check data quality with Apache Spark . But the real complexity lies in the greater data quality landscape, which involves people and processes, not just the Spark clusters.
To avoid such scenarios, organizations must prioritize data quality from the outset. They must develop a robust monitoring system to ensure data quality across all data pipeline stages. Furthermore, they must create a culture that values data quality and encourages every team member to own it. Managing a business is a complex undertaking that requires careful coordination and planning. Regarding data management, the process can be even more challenging. However, understanding the ETL process’s fundamental components can help you better understand how your data flows through your enterprise.
Extract, Transform, and Load
The ETL process - extract, transform, and load - is the backbone of most data-driven organizations. Every enterprise that deals with data needs to extract it from various sources, convert it to make it usable, and then load it into the target system. This process can be complex and involves multiple steps, each of which needs to be carefully managed to ensure data quality.
While the ETL process is just one part of the larger picture of enterprise management, it’s crucial. It’s the foundation upon which your data analytics and insights rest and any problems can significantly impact your business operations. Therefore, it’s essential to have a robust ETL process capable of handling your organization’s data needs.
Different tools like Databricks Workflows , Azure Data Factory , or Apache Airflow usually orchestrate the ETL process, or companies might even adopt their own job framework. This process moves the data around, making it usable for analysis and insights. But as companies start prioritizing data quality, they realize the importance of introducing data quality checks. They want to ensure that the data they’re using is accurate and reliable, and this is where things can get complicated.
Companies often ask questions like “Where do we need to run data quality checks?” and “How do we perform these checks?” The answer to these questions depends on the specific needs and requirements of the organization. Still, generally, data quality checks should be introduced at various points in the ETL process to ensure that data is valid, consistent, and trustworthy.
Introducing data quality checks into the ETL process is not a one-time event. It’s an ongoing effort that requires constant monitoring and management. As organizations evolve and grow, their data needs change, and so do their data quality requirements. Therefore, companies must remain vigilant and adapt their data quality checks to meet the changing needs of their business.
The most straightforward answer that will get you far is to include data quality checks in your ETL process. So whenever you create a table, make sure to define some of the data quality rules within the same file or even the same class. This way, metrics about its quality can be recorded whenever new data is added, including the number of unique records, missing values, and formatting issues. By including data quality checks as part of your ETL process, you can ensure that your data is always accurate and reliable.
And now things are happening in production. It’s more important to move fast, iterate fast, and don’t stop until you’re done. Companies should not wait until they have a perfect system in place before adding data quality checks. You are good to go if you move fast enough and add data quality a bit later. You have to do something with your data quality metrics. Of course, you need to display them in dashboards that will be presented to your on-call teams as contextualized links. So your dashboards might be in different toolings like Databricks SQL , Microsoft Power BI , or products like Tableau or Looker . The important thing is to ensure that the dashboards present the correct data clearly and understandably.
Alerting
You need to deliver the links to these contextualized dashboards through some alerting mechanisms. There are so many different ways of alerting in the modern-day ecosystem. But I recommend you to the standard tooling that you already have in your organization. So be it Nagios , Azure Monitor , AWS Simple Notification Service , or something else - just use it. Ensure to include a component in your alerting system that might be called a noise gate filter. What is a noise gate filter? So imagine you have 10 people on-call looking at all of the alerts, not only about your pipeline but also about your website latency or the health of your virtual machines or things like that. And people are so stressed, and they are looking at so many things. That’s the smaller number of alerts you’re sending them the better it is.
So having a successful machine-learned noise filtering mechanism in your alerting framework is essential for your on-call people to trust the alerts from your data quality. And it’s also necessary for upper management to trust your data because, essentially, whenever things go south, people on-call, even you, can receive the alert then and adequately fix the problem.
Finally, it’s worth noting that data quality checks are just the beginning.
Record-level versus Database-level
You might also ask: “Well, we have quality checks, but how do we actually make them?” And then, the concept of data profiling comes into play. To truly optimize your data quality, you’ll also need to incorporate data profiling into your process. Data profiling is analyzing data to understand its structure, quality, and content. Doing this lets you identify issues with your data before they become significant problems. Data profiling is generally part of more substantial enterprise data catalog initiatives. Still, sometimes it goes without it, more on than later.
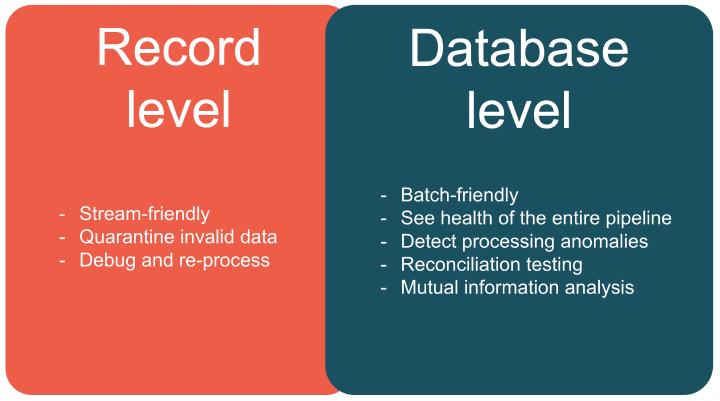
Nowadays, there are two fundamental approaches for ensuring data quality: record level and database level. Record-level data quality is stream-friendly and allows for the quarantine of invalid data for debugging and reprocessing at later stages. On the other hand, database-level data quality is batch by nature. It aims to detect processing anomalies to maintain the overall health of the data pipeline. Remember that while record-level data quality is essential, it cannot easily detect processing anomalies like database-level data quality can. In upcoming sections, we’ll dive deeper into relevance and validity in data quality.
Record-level data quality is stream-friendly and allows for invalid data to be quarantined for later debugging and reprocessing. On the other hand, database-level data quality is batch by nature and aims to see the health of the entire pipeline. It employs reconciliation testing and mutual information analysis techniques, which are difficult to implement with record-level data quality.
But which approach should you choose? The answer is both. You need to use both record-level and database-level data quality depending on your needs. Record-level data quality is ideal for current-time data that can be reprocessed later, while database-level data quality ensures the consistency of data sent.
And usually, on the whole-database-level quality testing, you employ reconciliation testing and mutual information analysis techniques, which you cannot do easily or fast enough when you are only doing record-level data quality. Do you need to pick one? No. Do you need to use both of them? By no means pick both of them and make sure you use more database-level or record-level data quality depending on needs. Remember, record level is one record at a time, and it’s possible to reprocess it later. Database-level quality is about making sure that the whole dataset is consistent.
Subject Matter Expertise
There are a couple of ways you can make data quality checks. And obviously, one may tell, ask subject matter experts because they know how to define the shape of data. Still, they may only partially cover some of the corner cases. And there might be more datasets than actual subject matter experts, and only relying on expertise would not get you far.
The other approach is exploration. With exploration, the people making the data quality checks are becoming the data experts. This happens when you onboard new data sources frequently enough and develop the subject matter expertise of what’s in those. Doing an exploration type of data quality check development may also result in lower coverage than necessary. And you may miss the failures once in a while, but still, it’s better than just relying on that mythical subject matter expertise, which is still to be acquired.

And the third approach is semi-supervised code generation of data quality rules. It heavily relies on profiling and helps data engineers who need to cover new datasets with automated tests quickly enough. Data engineers working with automated data quality rule generation frameworks may need to edit the generated code because generated code may overfit the rules with too strict criteria. People on call may receive too many alerts and stop trusting the alerts on data quality. Once you lose the trust of the alerting source, it’s tough to regain that, so make sure you don’t over-alert from the beginning. And the most important thing here is to use all these three techniques to develop quality rules because you need more than just relying on one to get you far.
Feature Engineering
One common approach is to use data quality libraries, which are available either as community-based or enterprise software tools. These libraries can be shipped as embeddable libraries or stand-alone platforms, depending on your organization’s needs. But more on those in the upcoming blog posts. All of these tools employ techniques like success keys. Essentially, the success key is 0 or 1 that are averaged to show the percentage of the number of all these records. It’s very SUM() and AVG() friendly. For example, you could use a success key to check whether an email address has a valid format. The other example is a column, that has 1 if all of the fields on this record are valid, otherwise 0. This gives the ability to get a percentage of total valid records. This technique is a variation of one-hot encoding
from the domain of machine learning.

Another technique could be called domain keys, which compare incoming data with previous datasets to ensure consistency. While this method may be slower, it can catch errors that success keys may miss. Dataset metrics are another tool in the data quality arsenal. This involves using materialized synthetic aggregations, like checking whether the number of records in an incoming batch is two standard deviations away from previous batches.
Reconciliation tests are another technique, where you repeat an entire computation independently to verify results. This is especially useful for double-entry bookkeeping, where the number of debit and credit dollars must balance out. By using these different techniques, you can develop a comprehensive data quality strategy that works for your organization. Just remember not to over-alert, as losing the trust of your team can be hard to recover from.
If you’ve enjoyed reading this article, then there’s a good chance that others will too! By sharing this article on social media using the buttons at the top of the page, you’re helping to spread valuable information to your network and potentially even beyond. Please subscribe to the RSS feed to stay up-to-date with the upcoming content.