Reflecting on the Year 2023
As we bid adieu to 2023, I’m thrilled to share the incredible journey of open-source work and innovation that unfolded throughout the year. It’s been a year marked by challenges, triumphs, and the relentless pursuit of excellence in tech and development.
Databricks SDK for Python
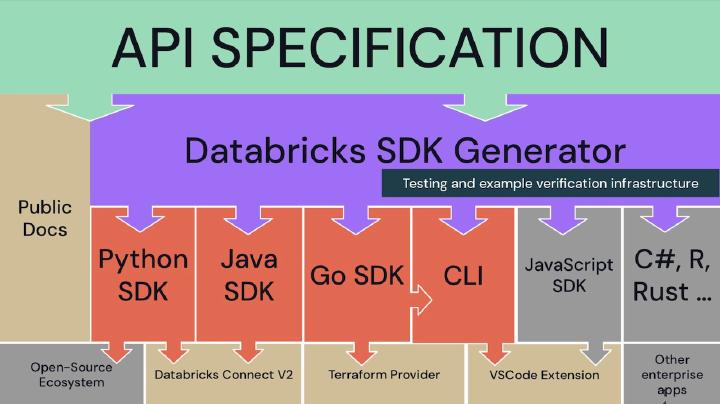
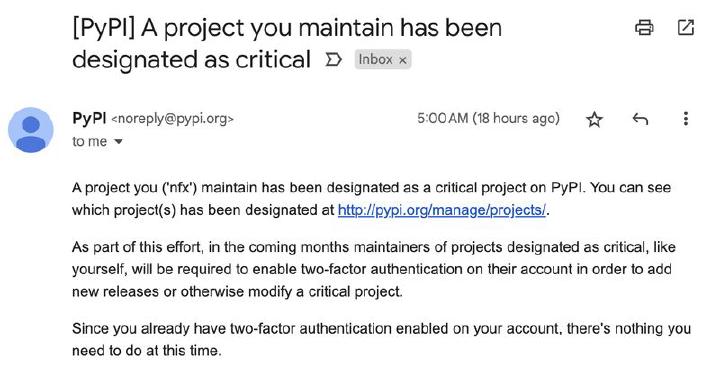
In April, I achieved a significant milestone with the launch of the Databricks SDK for Python . Running with roughly 3-4 million monthly downloads - isn’t that great? What makes it even more noteworthy is the ingenious infrastructure reuse from the previous year’s Go SDK for Databricks . Overcoming hurdles in a large organization with over 5000 people, I navigated the release under the Apache 2.0 license. I’ve approached driving adoption by implementing an integration test cross-compiler into runnable Python (and Go ) code examples over a hackathon in roughly 1000 lines of code, making it easier to maintain thousands of code examples over 7 different languages. And, according to this email from PyPI, it paid off:
Another challenge was integrating the Unified Authentication layer of Python SDK with gRPC transport interceptors so that all the recent versions of Databricks Connect can “just work” without any configuration with the SDK-enabled ecosystem, like using the same environment variables or magically picking up auth tokens from Azure CLI or Databricks CLI. It also required a change to Apache Spark .
Reboot of Databricks CLI
May saw the big reboot of Databricks CLI , which was rewritten from Python to Go. The main driver behind a complete rewrite was the simplicity of dependencies and packaging for Go apps - cross-compiling a static binary across all the required operating systems and platforms gave our team way more freedom of choice for power features. Python imposed a significant maintenance challenge with dependencies across all the necessary platforms and environments. Same code generation infrastructure as for Go SDK, Python SDK, and Java SDK, reused Unified Authentication layer . And great experimental interactivity features, like progress spinners for long-running operations or drop-downs for unfilled IDs.
Expanding the SDK ecosystem with Java and R
May saw the launch of the Java SDK for Databricks , adopting the same robust code generation infrastructure and authentication experience.
June brought forth the birth of the Databricks SDK for R , an experimental yet impactful addition to the SDK family. With a shared code generation infrastructure, this project broke ground despite my R coding hiatus since 2017. ChatGPT helped me to write the working core of services just within two days - I was mostly asking things like “How to translate this code in Go to R?” or “What does this code mean?” because R has quite a distinctive syntax and quite different idioms from all the languages I’m working with. However, the Advanced R book by Hadley Wickham helped me better understand the language and polish all the code generation templates right before the initial release. I initially thought R for Data Science book could help build better libraries, but that has a different focus. The journey to CRAN is ongoing, with a promising future for this experimental endeavor.
Nurturing Innovation in Databricks Labs
Throughout the year, I helped launch various projects within Databricks Labs, such as DiscoverX , Doc QA LLM chatbot , and DLT Meta . Ensuring the right design for long-term success became a priority, and the commitment to excellence in these projects mirrors the broader ethos of open-source development. November marked the rollout of the Contributor License Agreement (CLA) Assistant for Databricks Labs, enhancing our ability to track and accept external contributions. This move strengthens our commitment to fostering a vibrant and collaborative community.
Wrapping up the year in December, the launch of Databricks Labs Sandbox promises an even more experimental platform. With a consistent CLI front end and existing release infrastructure, this sandbox sets the stage for prototyping growth in the coming year.
Release Processes for the Shippable Software
Managing numerous tools and libraries with frequent releases is no small feat. This year, I’ve launched plenty of tools. Those require regular releases, each release taking approximately 20-40 minutes per library - regenerating code where necessary, documenting Public API differences and breaking changes, bumping the semantic version accordingly, collecting merged pull requests since the last release, updating the changelog file with all that (but in a way the release notes are editable), making that changelog part of the release pull request, waiting for the pull request to merge, tagging a commit on the main branch, pushing that tag and creating a GitHub release with the same release notes, as in the changelog. All these tools and libraries are released almost every other week. So I’ve decided to save many man-weeks-per-year by automating the release process to something between 2 and 15 minutes, depending on how fast CI runs and how well people make their pull request titles. This monumental step has streamlined our workflow, allowing for faster iterations and more frequent releases .
Technical Book Reviews

This year, I’ve tried myself as a technical book reviewer, volunteering time to read books before they see the print. Manning Publishing suggested reviewing two titles, drawing on my extensive experience in Go and Terraform development. Apparently, I have written most of the code in Go for the past couple of years, so I enjoyed reading Learn Concurrent Programming with Go by James Cutajar . It was an interesting angle compared to the one presented in Concurrency in Go by Katherine Cox-Buday . Since I created a Terraform provider, that has more than 20 million downloads , it was a pleasure for me to review some chapters of Terraform in Depth (MEAP) by Robert Hafner . There are not many books on the subject, so every fresh perspective benefits the practitioner community.
Getting a book out is a commitment that can easily take more than a year or so. It takes a lot of people to release a book, and hats off to the authors who made it.
More automation
September witnessed the launch of UCX , a project automating the upgrade of Databricks Workspaces from Hive Metastore to Unity Catalog. Leveraging the Python SDK from April, this venture is pivotal in advancing the SDK to a more production-ready state. Much effort was invested into productizing the collection of existing disparate scripts, failure recovery, automated integration testing infrastructure, and making the installation and upgrade journey easy for users.
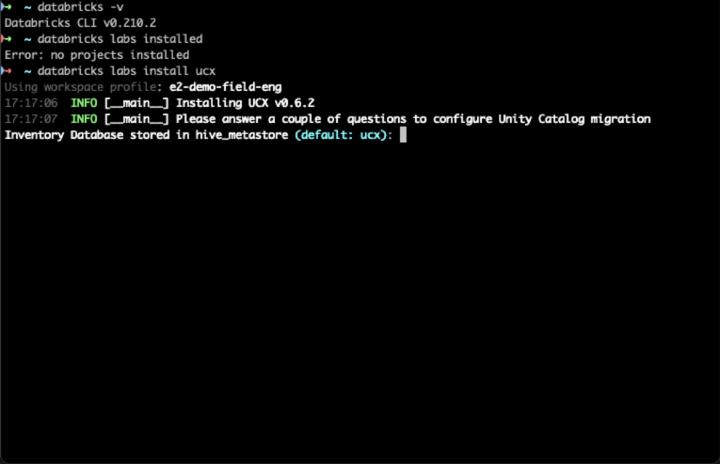
This was one of the reasons I created a plugin infrastructure
within Databricks CLI via the databricks labs command group so that all projects in Databricks Labs can have a consistent CLI and installation user experience. Luckily, the automated release infrastructure was already there and required only a bit of a change to apply it to more projects.
Writing more blogs
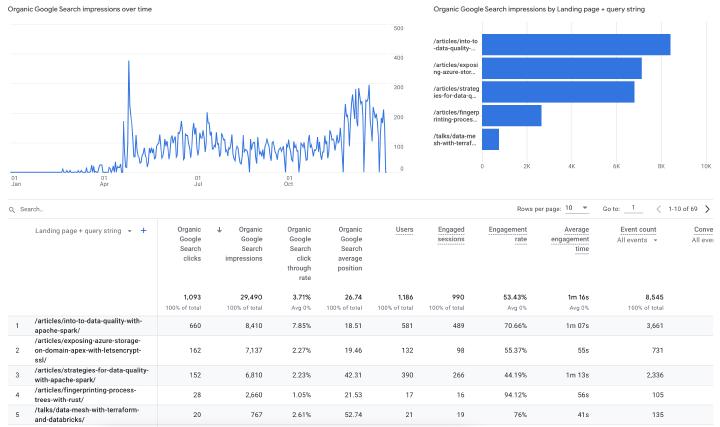
This year I experimented more with Search Engine Optimization (SEO) for this blog, and, according to Google Analytics, it started to work somewhere at the end of April, probably because of this article . I have plenty of public talks , that I still want to turn into nice and expanded articles - not the other way around. I mainly write for myself and appreciate when other people find it useful.
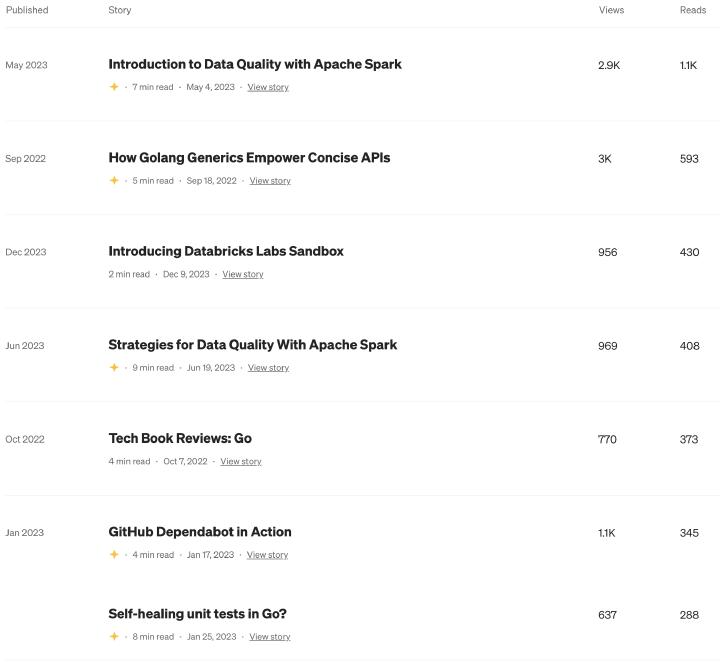
I’ve also started using Medium as a way to deliver release notes for Databricks Labs , but cannot tell if people like that or not - it’s only been there for less than two months.
In retrospect, 2023 has been a year of innovation, challenges met head-on and a relentless pursuit of excellence. As we eagerly anticipate the dawn of a new year, the lessons learned and achievements unlocked in the realm of open-source development will undoubtedly propel us toward even greater heights. Here’s to another year of groundbreaking contributions and collaborative success! 🚀