OSS Year 2022 in Review: Projects Launched
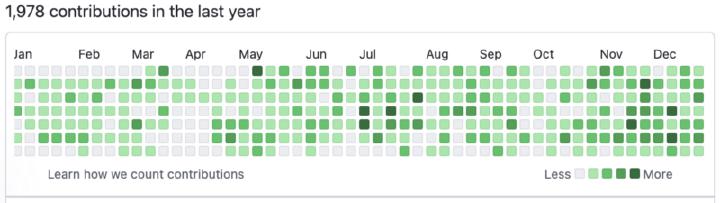
Okay, it’s this time of the year, and everyone is checking their GitHub stats. I’ll join the pack on my OSS summary for the year 2022. Here’s a short recap with my own thoughts about the four projects I’ve been driving.
Terraform Provider for Databricks
I started it in 2020 as a side project and tried Go programming language on something relatively serious. Besides, the tech was in the domain I’m passionate about — infrastructure automation and glorified editing of complicated JSON files. Two and a half years fast forward, and this plugin has reached the Top 5% of the whole Infrastructure-as-a-Code ecosystem by the amount of code, commits, contributors, and downloads. Perhaps that unbiased analysis would be a separate blog someday. I’ve also flipped it to proper v1.0 with all the relevant fuzz, like presenting it at several conferences . Huge kudos to the community of almost 120 contributors , and especially to Alex Ott and Vuong Nguyen.
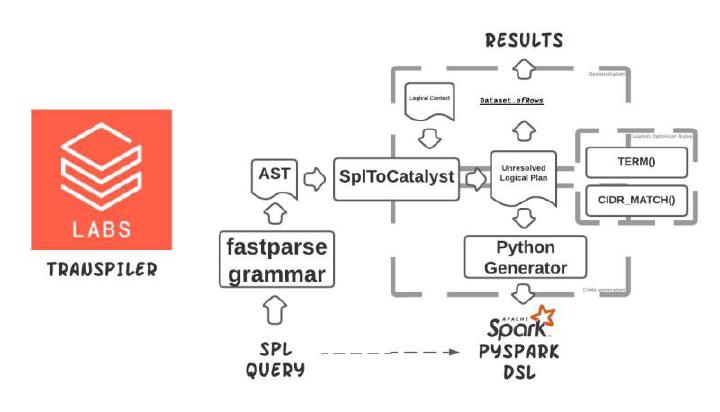
A cross-compiler from SPL to PySpark
Another thing I’m pretty passionate about is compiler research and development. At the end of 2021, I faced quite an ambiguous challenge of migrating hundreds of data pipelines from a language I had little idea about. Doing that manually could have been quite an ordeal. I’ve convinced Jason Trost to try automating this process by quickly crafting a proof-of-concept of a translating compiler, where AST was created with fastparse Scala library . Once I had the AST, those were relatively easy to map on Spark Catalyst nodes and generate PySpark dataframe DSL . Besides, this is not the first XXX-to-Spark cross-compiler I wrote — it’s relatively easy with Scala. And fastparse. Probably need to write a blog on a comparison of writing parsers in Scala and GoLang someday. Using Apache Spark since v0.15 or something, it was fun mapping concepts of the unfamiliar language to something I was familiar with, even on lower levels. Here’s the presentation if you’re curious. And if you enjoyed fastparse, consider supporting the library author by buying his Hands-on Scala book (just a recommendation).
Databricks SDK for Go
Another project I’ve managed to release in the open in 2022 is https://github.com/databricks/databricks-sdk-go , a story about code generation, the use of generics in Go, going through almost 400 different REST APIs, and so on. But one of the main reasons for creating it was to streamline the development of terraform provider. And a couple of other tools that I’ll talk about in the next year. I’ll be more confident in promoting it more widely once the Databricks terraform provider is fully integrated with it. Stay tuned.
Databricks Labs
From time to time, I help the Field Engineering of Databricks roll experimental projects into the open under the umbrella of Databricks Labs — that’s where the Databricks Terraform Provider was incubating for two years or so! In my occasional free time, I focus on software design quality, security posture, and release automation of these projects — like publishing to PyPI — https://pypi.org/user/databricks-labs/ , and ensuring that codebases have extended longevity, supported by the metrics. This year I’ve supported the launch of these awesome experimental projects:
- https://github.com/databrickslabs/mosaic — An extension to the Apache Spark framework that allows easy and fast processing of extensive geospatial datasets.
- https://github.com/databrickslabs/arcuate — Delta Sharing + MLflow for ML model & experiment exchange.
- https://github.com/databrickslabs/dbignite — This library is designed to provide a low friction entry to performing analytics on FHIR bundles by extracting patient resources and writing the data in Delta lake.
- https://github.com/databrickslabs/tika-ocr — experimental integration of Tika text recognition library with Databricks.
- https://github.com/databrickslabs/delta-sharing-java-connector — A Java connector for delta.io/sharing/ that allows you to ingest data on any JVM easily.
- https://github.com/databrickslabs/waterbear — Automated provisioning of an industry Lakehouse with the enterprise data model
Structured HTML table extraction with Go
When Go 1.18 came out, I wanted to experiment with their real applicability and see how embarrassingly far they were from those in Scala or Java. So I’ve decided to write the equivalent of pandas.read_html, but in Go, with generics and with almost no dependencies. I also needed to check how godoc worked with pkg.go.dev , but on a smaller scale. I’m surprised how my blog-post-ware got almost 99 stars on Github — https://github.com/nfx/go-htmltable — probably it’s useful for some people. I’d be surprised if it gets even more. Please check it out:
How Golang Generics Empower Concise APIs Learn how GitHub Dependabot is helping Open-Source projects to stay safe and up-to-date with automated dependency and security patch management in my other blog post:
This is a quick summary of projects I’ve launched or helped to launch in 2022. I hope that 2023 will be as fruitful as exciting things are coming. Stay tuned. And if you like the content, please follow me on GitHub or Twitter and comment on my posts. Your feedback is very welcome.