Open Source: Is It the Holy Grail or a Can of Worms?

Do you ever wonder if you should include a third-party library in your code or not? Sometimes it’s worth it, but mostly it’s not. Here’s a quick way to tell: If the library is doing something you don’t comprehend, or if it’s doing something you could do yourself with little effort, then don’t use it. The only exception to this rule is if the library is doing something that would be very difficult or time-consuming to do yourself. In that case, it might be worth using the library even if you don’t fully understand it.
Here’s a recent example from working with an external software vendor: I noticed jQuery as a dependency while reviewing a pull request. I was surprised: “Huh? Is anyone still using it in 2022?” and moved on to focus on critical functionality, leaving the comment asking the developer why we need jQuery in this project. The developer surprised me even more with the answer. They used jQuery just for onClick event handling (!!!). 300kb of extra bundled code to download. For a single handler. Even with the handler on document.body element, the vanilla JavaScript implementation is not that significant.
If you’re adding an external dependency, check if you’re using at least 50% of its functionality. Otherwise, not worth it.
Do you use more than 50% of the functionality in that dependency? Does the library have more than 1,000 lines of production code? Do you have a plan to use more than half of its Public API? Does the library have minimal external dependencies? Do you have the ability to replace that dependency with a custom solution?
If you answered “yes” to any of these questions, you should consider taking on the dependency. This means that you’re prepared to keep the dependency up-to-date, patch security vulnerabilities (more on that later), use all the features that matter to you, and keep an eye on the roadmap for future releases. Or don’t, and write everything from scratch — you have all the time in the world. When writing the library described in the previous article , I asked myself all these questions.
You don’t bring on a dependency alone, you bring dependencies of it and dependencies of its dependencies. Do always look at files like go.mod, pom.xml, setup.py, package.json. You’re looking at those files for licenses, right? You want to pick a branch from a tree, not the whole forest.
Websites like mvnrepository.com provide great dependency insights and must always be used before adding a dependency. This is exceptionally relevant for open source libraries: it’s not just your library getting the dependency. It’s hundreds or thousands of other projects getting it as well.

More than a decade ago, when kicking off a new enterprise software project, we were brainstorming the technology stack and went into an argument about which one to settle on. What happened next blew my mind back then: my colleague typed two different technology names into Google search and counted the number of results.
The technology with more results was declared the winner, which we ended up using. I was stunned because I had never seen anyone think like that. Remember — it was 2010. How about the quality of the code? How about the beauty of component design? But it turns out that my colleague was onto something: using Google search results as a proxy for quality is a surprisingly effective way to choose between two technologies.
There are a few reasons why this method works. First, when people are trying to learn about new technology, they often start by Googling it. So the number of results is a good proxy for the technology’s quality. Or is it? Second, it is a good indicator of how well-documented the technology is. If there are a lot of results, that means there are a lot of resources available to help you learn about the technology. Third, the number of results is a good proxy for how actively used the technology is. The bigger the number, the more people use the technology, and there is a good chance it is well-supported.
So, if you’re trying to choose between two technologies, you may use Google search results as a proxy for quality. But the number of results for a given query is not always a good indicator. The most popular technology is not always the best technology. The most popular technology is often the one that is better at marketing itself or the one that is better at getting people to talk about it. Haskell is beautiful, and all the software should be rewritten in Haskell, right? The other problem is that Google is not a perfect search engine. Finding the best resources for a given query is not always possible. So, even if you’re using Google as a proxy for quality, you may not be getting the best results.
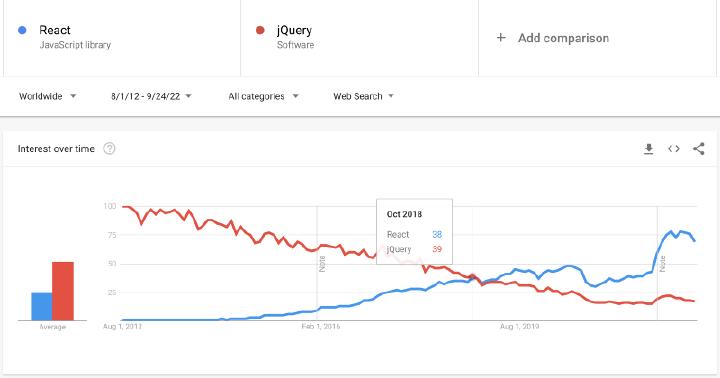
Can the number of search results alone inform you about the quality? Cobol has 11B results, but it doesn’t mean that it’s a well-documented technology in modern times. The number of questions on Stack Exchange can advise you about the popularity of technology. Does it suggest the quality? No.
The number of repositories on GitHub can brief you about the number of developers interested in a given technology. The number of articles in Google Trends can reveal the popularity of technology. jQuery had more search results than React before October 2018, but it doesn’t mean that jQuery is better technology. Did it inspire people? Yes. Is it in much use today? No.
Of course, software adoption trends are not always right, and betting on something is like a stock investment — you never know what may happen in the future. Just look at what happened with WireCard . Of course, it would help if you always did your due diligence. Evaluate the technology, the companies behind it, and the competition. And also, you should always have a backup plan. Or two.
The number of search results can indicate the popularity of technology, but it cannot tell you about the quality of the technology.
The last commit and release date are the other things I’m glancing at every time I select new tech. If the project has no commits for months/years, it’s a huge red flag for me. It’s easy to get caught up in the latest technology and want to use it in every project. But this is usually a bad idea. Plenty of libraries just don’t have enough time to mature, and it’s often hard to find support.
Oh, I forgot — it’s open source. There’s no support unless you go and fix it yourself. Or pay someone to do it. The number of project committers is a good indicator of a healthy community. Apply extra due diligence when only a few folks support the codebase. Please also remember that Linux was a one-person project for a while in its early days.
Releases are also a good indicator of the health of a project. If the community isn’t releasing new versions, it’s probably not getting the attention it needs. It’s essential to keep up with bug fixes and security issues. If you need a rock-solid foundation that can handle millions of users, using a technology that’s been around for 5–10 years might be a good idea. It’s essential to have a good understanding of the existing codebase and the tech you’re considering.
If you’re working on a greenfield project, you might have more leeway to choose a newer technology. I’ve been on several projects where we selected the tech stack based on the perceived coolness of the tech. The tech was new and shiny, and everyone wanted to use it. This was a lousy motivation, and products failed to launch on reasonable timelines.
I’m not even mentioning the security risk of third-party dependencies — there’s plenty of information written about the supply chain attacks in ATT&CK . Just recall the recent internet disaster with a very widely used and dull library, log4j . It has 140+ contributors , 134 releases, 12k+ commits, 3k+ stars, and a healthy community. And it has a small API surface. But it broke the internet. Should you write your logging library? Probably not. Should you keep the network perimeter secure? Definitely yes.
What can you do to ensure smoother operations and avoid unnecessary risks? Here are a few suggestions: Analyze the dependency tree. It should be easy to run a command in the package manager or use specialized vendor tools like the ones from Sonatype. Validate the dependency tree before changing it. The package manager tracks the dependencies, so you should be able to get their signatures and validate them against a safelist of known-good dependencies.
Learn how GitHub Dependabot is helping Open-Source projects to stay safe and up-to-date with automated dependency and security patch management.
Set up continuous monitoring of the dependency tree with GitHub dependabot or alternatives. It allows you to discover and fix issues early enough before they cause problems. Use the package manager to update dependencies to the latest version. If you follow these steps, you’ll be able to build a secure perimeter for your applications and avoid unnecessary risks.
This article may sound like written by Captain Hindsight from South Park :
P.S. I wrote this article with the help of the OpenAI GPT3 model, which completed some of my thoughts and was fun for drafts.