How Golang Generics Empower Concise APIs
You’ve likely heard and read dozens of stories about generics in Go about ordinary slices and maps but haven’t yet thought about a fun way to apply this feature. Let’s implement the peer of pandas.read_html , which maps HTML tables into slices of structs! If it’s achievable even with Rust , why shouldn’t it be with Go?! This essay will show you a thrilling mix of reflection and generics to reach concise external APIs for your libraries.
First, let’s look at the direct inspiration for this article — the most popular interactive data analysis library, Pandas : reading HTML seems to be so common that it’s deemed a commodity and thus, works outside of the box:
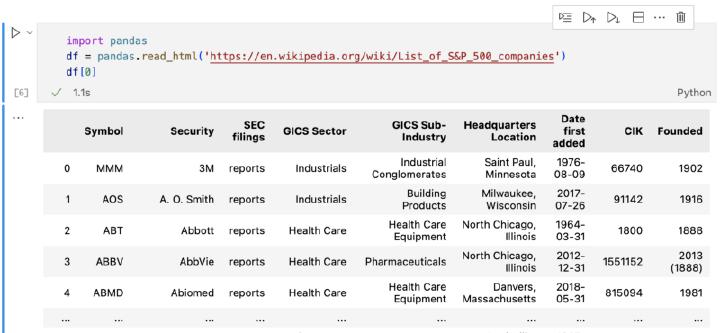
To follow the idiomatic table parsing example, let’s aim at taking S&P 500 list
from Wikipedia and turn it into a slice of Ticker instances, where we annotate every column with a table header name:
type Ticker struct {
Symbol string `header:"Symbol"`
Security string `header:"Security"`
CIK string `header:"CIK"`
}
url := "https://en.wikipedia.org/wiki/List_of_S&P_500_companies"
out, _ := htmltable.NewSliceFromURL[Ticker](url)
fmt.Println(out[0].Symbol)
fmt.Println(out[0].Security)
// Output:
// MMM
// 3M
Things could even be concise in Go
Something that we’ll pay attention to here will be [**Ticker**] from NewSliceFromURL**[Ticker]**(URL). This Go 1.18+ feature called type parameter
is our fancied way to tell to NewSliceFromURL the name of the type, where reflection will assist us in uncovering the names of headers. Before generics, you may have written a similar API as NewSliceFromURL(**Ticker{},** URL), though I always found it moderately confusing:
Why do we need to pass the empty instance of type if our objective is passing just the type?
Having spent numerous years writing Java code, I’ve gotten used to the concept of “object mapping” from libraries like Jackson . But this blog is about Go, and you’ve probably landed here to figure out how to achieve a similar thing. You may have assumed that Go generics “just work,” but your level of enjoyment depends on your affinity to the other programming ecosystems. As of the time of this writing, methods cannot yet have type parameters , which “opens the flood gates of creativity” for API design. Here’s the illustration:

It looks a bit like magic, but here’s the simplified way of thinking about it: when we call theNewSliceFromURL**[Ticker]**(), __ the compiler substitutes type parameter references with the actual type, and dummy T in feeder[T] type becomes dummy Ticker. Still hard to follow, but thrilling? Please read a couple of introductory
articles
(or more
advanced
ones).
So, now we have a dummy Ticker and need to read some metadata from it. First, we get reflect.Value
from our dummy Ticker, then we get the
Ticker
type
into the elem variable, from which we can discover the number of fields
of a type and iterate over them.
Now we need to tie Ticker fields to table headers. In Java, you would have probably created an @Header annotation and used a whole structured framework
around it.
Still, in Go, one has to follow a convention where and write “tag strings” of optionally space-separated key:"value" pairs, which we could read via the Get
method
of Tag property of the struct field.
// Your typical parsing of struct field tags
func (f *feeder[T]) headers() ([]string, map[string]int, error) {
dt := reflect.ValueOf(f.dummy)
elem := dt.Type()
headers := []string{}
fields := map[string]int{}
for i := 0; i < elem.NumField(); i++ {
field := elem.Field(i)
header := field.Tag.Get("header")
if header == "" {
continue
}
// ... skipped for clarity
fields[header] = i
headers = append(headers, header)
}
return headers, fields, nil
}
Once we get the struct field position mapping, we have to match it with table header column positions, which we’ll discuss later in this post:
// Marry what our struct understands with what is in the HTML table
func (f *feeder[T]) table() (*tableData, map[int]int, error) {
headers, fields, err := f.headers()
if err != nil {
return nil, nil, err
}
table, err := f.FindWithColumns(headers...)
if err != nil {
return nil, nil, err
}
mapping := map[int]int{}
for idx, header := range table.header {
field, ok := fields[header]
if !ok {
continue
}
mapping[idx] = field
}
return table, mapping, nil
}
The mapping and data are all there, and we’re ready to reflect it on a slice we create. Interesting bits here relate to making a slice and casting this slice to a concrete type.
Given that we have all table data already in memory, we can MakeSlice with predefined capacity and length to avoid unnecessary dynamic growing of the slice. MakeSlice returns a slice value, which we’ll use to access individual items with the slice by their position.
This code snippet assumes strings as the only supported data type for our table cells. Once we’ve added all the table rows to our slice, we have to cast it: Interface() method will convert reflect value to **any**, and .([]T) will get us **[]Ticker**.
// reflect.MakeSlice() creates a value where you add new elements via the Index() method.
func (f *feeder[T]) slice() ([]T, error) {
table, mapping, err := f.table()
if err != nil {
return nil, err
}
dummy := reflect.ValueOf(f.dummy)
dt := dummy.Type()
sliceValue := reflect.MakeSlice(reflect.SliceOf(dt),
len(table.rows), len(table.rows))
for rowIdx, row := range table.rows {
item := sliceValue.Index(rowIdx)
for idx, field := range mapping {
// only strings, for clarity
item.Field(field).SetString(row[idx])
}
}
return sliceValue.Interface().([]T), nil
}
And the beautiful API you’ve seen at the start of the page is backed by roughly the following exported package function, which is just responsible for the type reference propagation by the compiler and calling initializers for a couple of things:
// Package level wrapper is needed to hide the complexities of dummy variables
func NewSliceFromURL[T any](url string) ([]T, error) {
resp, err := http.Get(url)
if err != nil {
return nil, err
}
defer resp.Body.Close()
f := &feeder[T]{
page: page{ctx: resp.Request.Context()},
}
f.init(resp.Body)
return f.slice()
}
Remember: unlike reflection in other languages, you refer to a field by its position in the struct, not the name. Field order sometimes affects performance, but we’re using reflection here, so performance suffers slightly anyway.
But in this case, it’s less critical than the clarity of Public APIs.
To sum up: Every time we work with annotated classes, we have to parse the annotated fields.
func (f *feeder[T]) headers() ([]string, map[string]int, error) {
dt := reflect.ValueOf(f.dummy)
elem := dt.Type()
headers := []string{}
fields := map[string]int{}
for i := 0; i < elem.NumField(); i++ {
field := elem.Field(i)
header := field.Tag.Get("header")
if header == "" {
continue
}
// ... skipped for clarity
fields[header] = i
headers = append(headers, header)
}
return headers, fields, nil
}
Now that we’ve played with reflection enough let’s get some data. You may also be inclined to consume a table without any custom type creation and use plain old callbacks. As a library author, you could add methods like Each, Each2, Each3, and so on. It’s common for Java with method overloading. Just look at log4j sources. But for GoLang, we have to be pretty chatty:
// Plain old callbacks for iteration
_ = page.Each2("c", "d", func(c, d string) error {
fmt.Printf("c:%s d:%s\n", c, d)
return nil
})
Routing data into the callback is relatively straightforward because we only need to figure out the table header’s position and match it with supplied column names. More specific than the reflection approach, but it scales only to a couple of columns. You don’t want to maintain too many verbose methods in the single type, and for the sake of simplicity, we’ll have only Each, Each2, and Each3:
// Maintaining concise APIs and error propagation in Go requires almost copy-paste.
func (p *page) Each2(a, b string, f func(a, b string) error) error {
table, err := p.FindWithColumns(a, b)
if err != nil {
return err
}
offsets := map[string]int{}
for idx, header := range table.header {
offsets[header] = idx
}
_1, _2 := offsets[a], offsets[b]
for idx, row := range table.rows {
err = f(row[_1], row[_2])
if err != nil {
return fmt.Errorf("row %d: %w", idx, err)
}
}
return nil
}
How do we understand which table to pick on the HTML page? It may have multiple. And Pandas library didn’t solve the “developer experience” problem well enough. So let’s add some uncomplicated heuristics of matching tables by column names. It should work in 99% of the cases because pages with tables as data have one table tag on average, occasionally two, and seldom three. It’s the second decade of the XXI century, and nearly nobody uses HTML for layouts.
// Great error messages are essential for fuzzy matching.
func (p *page) FindWithColumns(columns ...string) (*tableData, error) {
// realistic p won't have this much
found := 0xfffffff
for idx, table := range p.tables {
matchedColumns := 0
for _, col := range columns {
for _, header := range table.header {
if col == header {
// perform fuzzy matching of table headers
matchedColumns++
}
}
}
if matchedColumns != len(columns) {
continue
}
if found < len(p.tables) {
// and do a best-effort error message, that is cleaner than pandas.read_html
return nil, fmt.Errorf("more than one table matches columns `%s`: "+
"[%d] %s and [%d] %s", strings.Join(columns, ", "),
found, p.tables[found], idx, p.tables[idx])
}
found = idx
}
if found > len(p.tables) {
return nil, fmt.Errorf("cannot find table with columns: %s",
strings.Join(columns, ", "))
}
return p.tables[found], nil
}
We get the table data on the lowest level via the golang.org/x/net/html
package by making a simple recursive parser. Of course, we could do it with goquery
(which is also built on top of x/net/html), but we may make out code simpler by avoiding two extra transitive dependencies. If you, as an audience, are interested in the write-up of technique comparison — please leave a comment below, and I’ll see what we can do.
// simple parsing of HTML tables in Go standard (experimental) library
func (p *page) parse(n *html.Node) {
if n == nil {
return
}
switch n.Data {
case "td", "th":
var sb strings.Builder
p.innerText(n, &sb)
p.row = append(p.row, sb.String())
return
case "tr":
p.finishRow()
case "table":
p.finishTable()
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
p.parse(c)
}
}
Resources
- HTML5-compliant tokenizer and parser in Go
- goquery — like jQuery, but in Go
- Introduction to Annotations in Java
- reflect package in Go
- Intro to Generics in Go: Type Parameters, Type Inference, and Constraints
- Generics and Value Types in Golang
- Tech Book Reviews: Go
- GitHub - nfx/go-htmltable: Structured HTML table data extraction from URLs in Go that has almost no…