Building Databricks Integrations With Go
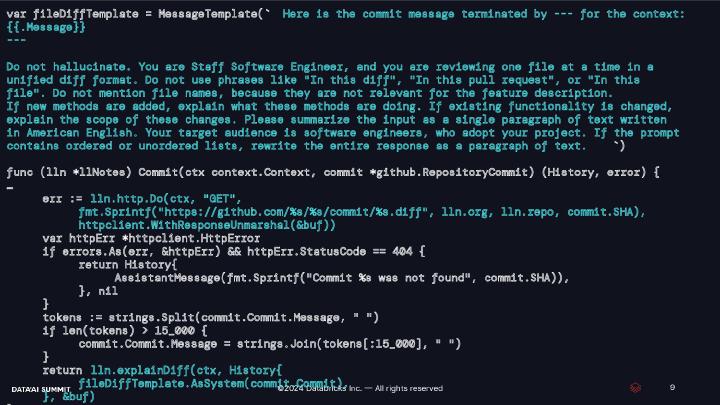
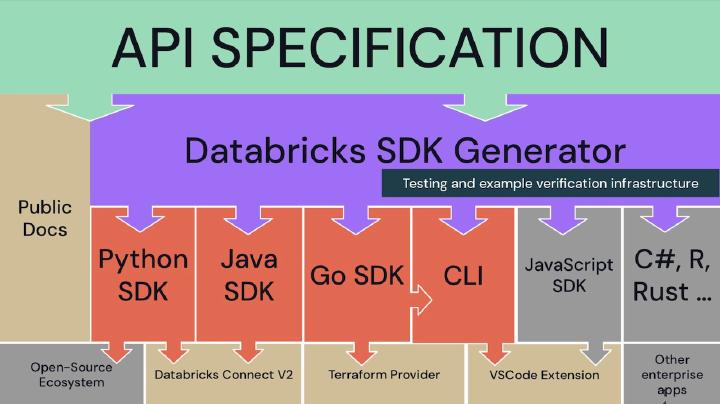
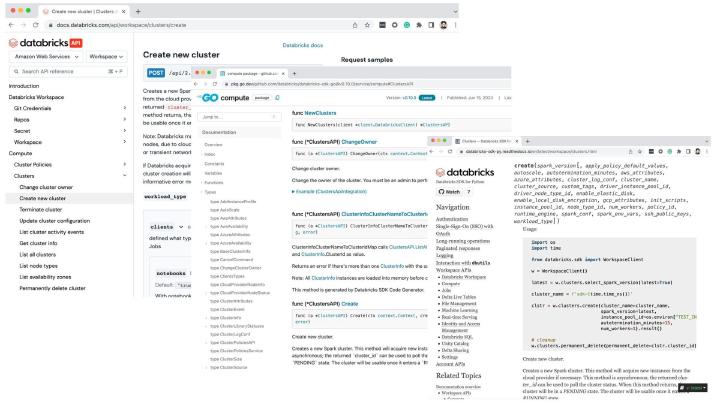
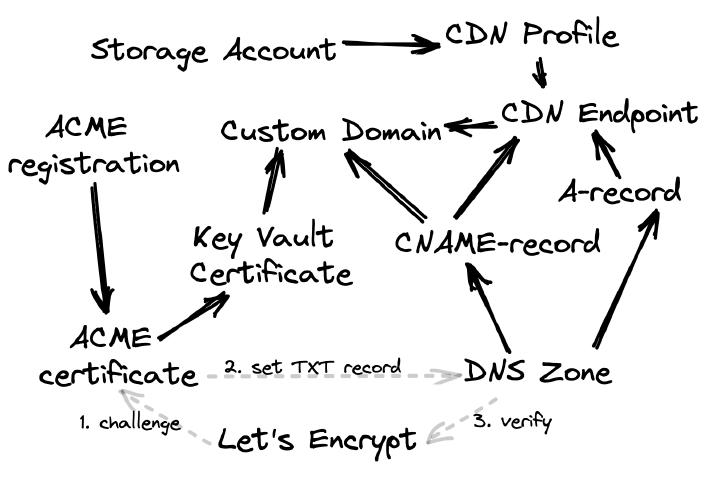
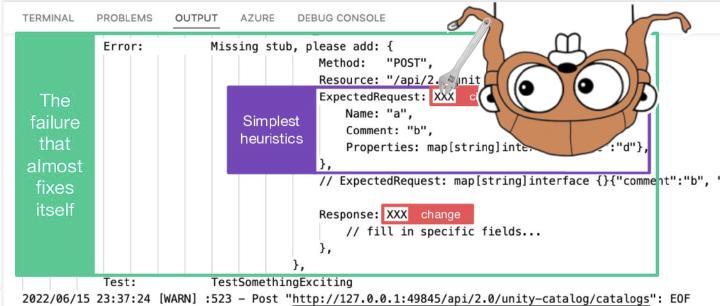
This talk highlights the transformative impact of the Databricks SDK for Go, enhancing development through seamless deployment, simplified packaging, and enriched user experiences. We will focus on two key examples: the Databricks CLI and Databricks Labs Watchdog, demonstrating the SDK’s potential.
Read more about Building Databricks integrations with Go